
What is AI? Artificial Intelligence Tutorial for Beginners
What is AI?
A machine with the ability to perform cognitive functions such as perceiving, learning, reasoning and solve problems are deemed to hold an artificial intelligence.
Artificial intelligence exists when a machine has cognitive ability. The benchmark for AI is the human level concerning reasoning, speech, and vision.
In this basic tutorial, you will learn-
- What is AI?
- Introduction to AI Levels
- A brief History of Artificial Intelligence
- Type of Artificial Intelligence
- Where is AI used? Examples
- Why is AI booming now?
Introduction to AI Levels
- Narrow AI: A artificial intelligence is said to be narrow when the machine can perform a specific task better than a human. The current research of AI is here now
- General AI: An artificial intelligence reaches the general state when it can perform any intellectual task with the same accuracy level as a human would
- Strong AI: An AI is strong when it can beat humans in many tasks
Nowadays, AI is used in almost all industries, giving a technological edge to all companies integrating AI at scale. According to McKinsey, AI has the potential to create 600 billions of dollars of value in retail, bring 50 percent more incremental value in banking compared with other analytics techniques. In transport and logistic, the potential revenue jump is 89 percent more.
Concretely, if an organization uses AI for its marketing team, it can automate mundane and repetitive tasks, allowing the sales representative to focus on tasks like relationship building, lead nurturing, etc. A company name Gong provides a conversation intelligence service. Each time a Sales Representative make a phone call, the machine records transcribes and analyzes the chat. The VP can use AI analytics and recommendation to formulate a winning strategy.
In a nutshell, AI provides a cutting-edge technology to deal with complex data which is impossible to handle by a human being. AI automates redundant jobs allowing a worker to focus on the high level, value-added tasks. When AI is implemented at scale, it leads to cost reduction and revenue increase.
A brief History of Artificial Intelligence
Artificial intelligence is a buzzword today, although this term is not new. In 1956, a group of avant-garde experts from different backgrounds decided to organize a summer research project on AI. Four bright minds led the project; John McCarthy (Dartmouth College), Marvin Minsky (Harvard University), Nathaniel Rochester (IBM), and Claude Shannon (Bell Telephone Laboratories).
The primary purpose of the research project was to tackle "every aspect of learning or any other feature of intelligence that can in principle be so precisely described, that a machine can be made to simulate it."
The proposal of the summits included
- Automatic Computers
- How Can a Computer Be Programmed to Use a Language?
- Neuron Nets
- Self-improvement
It led to the idea that intelligent computers can be created. A new era began, full of hope - Artificial intelligence.
Type of Artificial Intelligence
Artificial intelligence can be divided into three subfields:
- Artificial intelligence
- Machine learning
- Deep learning

Machine Learning
Machine learning is the art of study of algorithms that learn from examples and experiences.
Machine learning is based on the idea that there exist some patterns in the data that were identified and used for future predictions.
The difference from hardcoding rules is that the machine learns on its own to find such rules.
Deep learning
Deep learning is a sub-field of machine learning. Deep learning does not mean the machine learns more in-depth knowledge; it means the machine uses different layers to learn from the data. The depth of the model is represented by the number of layers in the model. For instance, Google LeNet model for image recognition counts 22 layers.
In deep learning, the learning phase is done through a neural network. A neural network is an architecture where the layers are stacked on top of each other.
AI vs. Machine Learning
Most of our smartphone, daily device or even the internet uses Artificial intelligence. Very often, AI and machine learning are used interchangeably by big companies that want to announce their latest innovation. However, Machine learning and AI are different in some ways.
AI- artificial intelligence- is the science of training machines to perform human tasks. The term was invented in the 1950s when scientists began exploring how computers could solve problems on their own.

Artificial Intelligence is a computer that is given human-like properties. Take our brain; it works effortlessly and seamlessly to calculate the world around us. Artificial Intelligence is the concept that a computer can do the same. It can be said that AI is the large science that mimics human aptitudes.
Machine learning is a distinct subset of AI that trains a machine how to learn. Machine learning models look for patterns in data and try to conclude. In a nutshell, the machine does not need to be explicitly programmed by people. The programmers give some examples, and the computer is going to learn what to do from those samples.
Where is AI used? Examples
AI has broad applications-
- Artificial intelligence is used to reduce or avoid the repetitive task. For instance, AI can repeat a task continuously, without fatigue. In fact, AI never rests, and it is indifferent to the task to carry out
- Artificial intelligence improves an existing product. Before the age of machine learning, core products were building upon hard-code rule. Firms introduced artificial intelligence to enhance the functionality of the product rather than starting from scratch to design new products. You can think of a Facebook image. A few years ago, you had to tag your friends manually. Nowadays, with the help of AI, Facebook gives you a friend's recommendation.
AI is used in all the industries, from marketing to supply chain, finance, food-processing sector. According to a McKinsey survey, financial services and high tech communication are leading the AI fields.

Why is AI booming now?

A neural network has been out since the nineties with the seminal paper of Yann LeCun. However, it started to become famous around the year 2012. Explained by three critical factors for its popularity are:
- Hardware
- Data
- Algorithm
Machine learning is an experimental field, meaning it needs to have data to test new ideas or approaches. With the boom of the internet, data became more easily accessible. Besides, giant companies like NVIDIA and AMD have developed high-performance graphics chips for the gaming market.
Hardware
In the last twenty years, the power of the CPU has exploded, allowing the user to train a small deep-learning model on any laptop. However, to process a deep-learning model for computer vision or deep learning, you need a more powerful machine. Thanks to the investment of NVIDIA and AMD, a new generation of GPU (graphical processing unit) are available. These chips allow parallel computations. It means the machine can separate the computations over several GPU to speed up the calculations.
For instance, with an NVIDIA TITAN X, it takes two days to train a model called ImageNet against weeks for a traditional CPU. Besides, big companies use clusters of GPU to train deep learning model with the NVIDIA Tesla K80 because it helps to reduce the data center cost and provide better performances.

Data
Deep learning is the structure of the model, and the data is the fluid to make it alive. Data powers the artificial intelligence. Without data, nothing can be done. Latest Technologies have pushed the boundaries of data storage. It is easier than ever to store a high amount of data in a data center.
Internet revolution makes data collection and distribution available to feed machine learning algorithm. If you are familiar with Flickr, Instagram or any other app with images, you can guess their AI potential. There are millions of pictures with tags available on these websites. Those pictures can be used to train a neural network model to recognize an object on the picture without the need to manually collect and label the data.
Artificial Intelligence combined with data is the new gold. Data is a unique competitive advantage that no firm should neglect. AI provides the best answers from your data. When all the firms can have the same technologies, the one with data will have a competitive advantage over the other. To give an idea, the world creates about 2.2 exabytes, or 2.2 billion gigabytes, every day.
A company needs exceptionally diverse data sources to be able to find the patterns and learn and in a substantial volume.

Algorithm
Hardware is more powerful than ever, data is easily accessible, but one thing that makes the neural network more reliable is the development of more accurate algorithms. Primary neural networks are a simple multiplication matrix without in-depth statistical properties. Since 2010, remarkable discoveries have been made to improve the neural network
Artificial intelligence uses a progressive learning algorithm to let the data do the programming. It means, the computer can teach itself how to perform different tasks, like finding anomalies, become a chatbot.
Summary
Artificial intelligence and machine learning are two confusing terms. Artificial intelligence is the science of training machine to imitate or reproduce human task. A scientist can use different methods to train a machine. At the beginning of the AI's ages, programmers wrote hard-coded programs, that is, type every logical possibility the machine can face and how to respond. When a system grows complex, it becomes difficult to manage the rules. To overcome this issue, the machine can use data to learn how to take care of all the situations from a given environment.
The most important features to have a powerful AI is to have enough data with considerable heterogeneity. For example, a machine can learn different languages as long as it has enough words to learn from.
AI is the new cutting-edge technology. Ventures capitalist are investing billions of dollars in startups or AI project. McKinsey estimates AI can boost every industry by at least a double-digit growth rate.
Machine Learning Tutorial for Beginners
What is Machine Learning?
Machine Learning is a system that can learn from example through self-improvement and without being explicitly coded by programmer. The breakthrough comes with the idea that a machine can singularly learn from the data (i.e., example) to produce accurate results.
Machine learning combines data with statistical tools to predict an output. This output is then used by corporate to makes actionable insights. Machine learning is closely related to data mining and Bayesian predictive modeling. The machine receives data as input, use an algorithm to formulate answers.
A typical machine learning tasks are to provide a recommendation. For those who have a Netflix account, all recommendations of movies or series are based on the user's historical data. Tech companies are using unsupervised learning to improve the user experience with personalizing recommendation.
Machine learning is also used for a variety of task like fraud detection, predictive maintenance, portfolio optimization, automatize task and so on.
In this basic tutorial, you will learn-
- What is Machine Learning?
- Machine Learning vs. Traditional Programming
- How does machine learning work?
- Machine learning Algorithms and where they are used?
- How to choose Machine Learning Algorithm
- Challenges and Limitations of Machine learning
- Application of Machine learning
- Why is machine learning important?
Machine Learning vs. Traditional Programming
Traditional programming differs significantly from machine learning. In traditional programming, a programmer code all the rules in consultation with an expert in the industry for which software is being developed. Each rule is based on a logical foundation; the machine will execute an output following the logical statement. When the system grows complex, more rules need to be written. It can quickly become unsustainable to maintain.

Machine learning is supposed to overcome this issue. The machine learns how the input and output data are correlated and it writes a rule. The programmers do not need to write new rules each time there is new data. The algorithms adapt in response to new data and experiences to improve efficacy over time.

How does Machine learning work?
Machine learning is the brain where all the learning takes place. The way the machine learns is similar to the human being. Humans learn from experience. The more we know, the more easily we can predict. By analogy, when we face an unknown situation, the likelihood of success is lower than the known situation. Machines are trained the same. To make an accurate prediction, the machine sees an example. When we give the machine a similar example, it can figure out the outcome. However, like a human, if its feed a previously unseen example, the machine has difficulties to predict.
The core objective of machine learning is the learning and inference. First of all, the machine learns through the discovery of patterns. This discovery is made thanks to the data. One crucial part of the data scientist is to choose carefully which data to provide to the machine. The list of attributes used to solve a problem is called a feature vector. You can think of a feature vector as a subset of data that is used to tackle a problem.
The machine uses some fancy algorithms to simplify the reality and transform this discovery into a model. Therefore, the learning stage is used to describe the data and summarize it into a model.

For instance, the machine is trying to understand the relationship between the wage of an individual and the likelihood to go to a fancy restaurant. It turns out the machine finds a positive relationship between wage and going to a high-end restaurant: This is the model
Inferring
When the model is built, it is possible to test how powerful it is on never-seen-before data. The new data are transformed into a features vector, go through the model and give a prediction. This is all the beautiful part of machine learning. There is no need to update the rules or train again the model. You can use the model previously trained to make inference on new data.

The life of Machine Learning programs is straightforward and can be summarized in the following points:
- Define a question
- Collect data
- Visualize data
- Train algorithm
- Test the Algorithm
- Collect feedback
- Refine the algorithm
- Loop 4-7 until the results are satisfying
- Use the model to make a prediction
Once the algorithm gets good at drawing the right conclusions, it applies that knowledge to new sets of data.
Machine learning Algorithms and where they are used?

Machine learning can be grouped into two broad learning tasks: Supervised and Unsupervised. There are many other algorithms
Supervised learning
An algorithm uses training data and feedback from humans to learn the relationship of given inputs to a given output. For instance, a practitioner can use marketing expense and weather forecast as input data to predict the sales of cans.
You can use supervised learning when the output data is known. The algorithm will predict new data.
There are two categories of supervised learning:
- Classification task
- Regression task
Classification
Imagine you want to predict the gender of a customer for a commercial. You will start gathering data on the height, weight, job, salary, purchasing basket, etc. from your customer database. You know the gender of each of your customer, it can only be male or female. The objective of the classifier will be to assign a probability of being a male or a female (i.e., the label) based on the information (i.e., features you have collected). When the model learned how to recognize male or female, you can use new data to make a prediction. For instance, you just got new information from an unknown customer, and you want to know if it is a male or female. If the classifier predicts male = 70%, it means the algorithm is sure at 70% that this customer is a male, and 30% it is a female.
The label can be of two or more classes. The above example has only two classes, but if a classifier needs to predict object, it has dozens of classes (e.g., glass, table, shoes, etc. each object represents a class)
Regression
When the output is a continuous value, the task is a regression. For instance, a financial analyst may need to forecast the value of a stock based on a range of feature like equity, previous stock performances, macroeconomics index. The system will be trained to estimate the price of the stocks with the lowest possible error.
| Algorithm Name | Description | Type |
| Linear regression | Finds a way to correlate each feature to the output to help predict future values. | Regression |
| Logistic regression | Extension of linear regression that's used for classification tasks. The output variable 3is binary (e.g., only black or white) rather than continuous (e.g., an infinite list of potential colors) | Classification |
| Decision tree | Highly interpretable classification or regression model that splits data-feature values into branches at decision nodes (e.g., if a feature is a color, each possible color becomes a new branch) until a final decision output is made | Regression Classification |
| Naive Bayes | The Bayesian method is a classification method that makes use of the Bayesian theorem. The theorem updates the prior knowledge of an event with the independent probability of each feature that can affect the event. | Regression Classification |
| Support vector machine | Support Vector Machine, or SVM, is typically used for the classification task. SVM algorithm finds a hyperplane that optimally divided the classes. It is best used with a non-linear solver. | Regression (not very common) Classification |
| Random forest | The algorithm is built upon a decision tree to improve the accuracy drastically. Random forest generates many times simple decision trees and uses the 'majority vote' method to decide on which label to return. For the classification task, the final prediction will be the one with the most vote; while for the regression task, the average prediction of all the trees is the final prediction. | Regression Classification |
| AdaBoost | Classification or regression technique that uses a multitude of models to come up with a decision but weighs them based on their accuracy in predicting the outcome | Regression Classification |
| Gradient-boosting trees | Gradient-boosting trees is a state-of-the-art classification/regression technique. It is focusing on the error committed by the previous trees and tries to correct it. | Regression Classification |
Unsupervised learning
In unsupervised learning, an algorithm explores input data without being given an explicit output variable (e.g., explores customer demographic data to identify patterns)
You can use it when you do not know how to classify the data, and you want the algorithm to find patterns and classify the data for you
| Algorithm | Description |
Type
|
K-means clustering
|
Puts data into some groups (k) that each contains data with similar characteristics (as determined by the model, not in advance by humans)
|
Clustering
|
Gaussian mixture model
|
A generalization of k-means clustering that provides more flexibility in the size and shape of groups (clusters
|
Clustering
|
Hierarchical clustering
|
Splits clusters along a hierarchical tree to form a classification system.
Can be used for Cluster loyalty-card customer
|
Clustering
|
Recommender system
|
Help to define the relevant data for making a recommendation.
|
Clustering
|
PCA/T-SNE
|
Mostly used to decrease the dimensionality of the data. The algorithms reduce the number of features to 3 or 4 vectors with the highest variances.
|
Dimension Reduction
|
How to choose Machine Learning Algorithm
There are plenty of machine learning algorithms. The choice of the algorithm is based on the objective.
In the example below, the task is to predict the type of flower among the three varieties. The predictions are based on the length and the width of the petal. The picture depicts the results of ten different algorithms. The picture on the top left is the dataset. The data is classified into three categories: red, light blue and dark blue. There are some groupings. For instance, from the second image, everything in the upper left belongs to the red category, in the middle part, there is a mixture of uncertainty and light blue while the bottom corresponds to the dark category. The other images show different algorithms and how they try to classified the data.

Challenges and Limitations of Machine learning
The primary challenge of machine learning is the lack of data or the diversity in the dataset. A machine cannot learn if there is no data available. Besides, a dataset with a lack of diversity gives the machine a hard time. A machine needs to have heterogeneity to learn meaningful insight. It is rare that an algorithm can extract information when there are no or few variations. It is recommended to have at least 20 observations per group to help the machine learn. This constraint leads to poor evaluation and prediction.
Application of Machine learning
Augmentation:
- Machine learning, which assists humans with their day-to-day tasks, personally or commercially without having complete control of the output. Such machine learning is used in different ways such as Virtual Assistant, Data analysis, software solutions. The primary user is to reduce errors due to human bias.
Automation:
- Machine learning, which works entirely autonomously in any field without the need for any human intervention. For example, robots performing the essential process steps in manufacturing plants.
Finance Industry
- Machine learning is growing in popularity in the finance industry. Banks are mainly using ML to find patterns inside the data but also to prevent fraud.
Government organization
- The government makes use of ML to manage public safety and utilities. Take the example of China with the massive face recognition. The government uses Artificial intelligence to prevent jaywalker.
Healthcare industry
- Healthcare was one of the first industry to use machine learning with image detection.
Marketing
- Broad use of AI is done in marketing thanks to abundant access to data. Before the age of mass data, researchers develop advanced mathematical tools like Bayesian analysis to estimate the value of a customer. With the boom of data, marketing department relies on AI to optimize the customer relationship and marketing campaign.
Example of application of Machine Learning in Supply Chain
Machine learning gives terrific results for visual pattern recognition, opening up many potential applications in physical inspection and maintenance across the entire supply chain network.
Unsupervised learning can quickly search for comparable patterns in the diverse dataset. In turn, the machine can perform quality inspection throughout the logistics hub, shipment with damage and wear.
For instance, IBM's Watson platform can determine shipping container damage. Watson combines visual and systems-based data to track, report and make recommendations in real-time.
In past year stock manager relies extensively on the primary method to evaluate and forecast the inventory. When combining big data and machine learning, better forecasting techniques have been implemented (an improvement of 20 to 30 % over traditional forecasting tools). In term of sales, it means an increase of 2 to 3 % due to the potential reduction in inventory costs.
Example of Machine Learning Google Car
For example, everybody knows the Google car. The car is full of lasers on the roof which are telling it where it is regarding the surrounding area. It has radar in the front, which is informing the car of the speed and motion of all the cars around it. It uses all of that data to figure out not only how to drive the car but also to figure out and predict what potential drivers around the car are going to do. What's impressive is that the car is processing almost a gigabyte a second of data.

Why is Machine Learning important?
Machine learning is the best tool so far to analyze, understand and identify a pattern in the data. One of the main ideas behind machine learning is that the computer can be trained to automate tasks that would be exhaustive or impossible for a human being. The clear breach from the traditional analysis is that machine learning can take decisions with minimal human intervention.
Take the following example; a retail agent can estimate the price of a house based on his own experience and his knowledge of the market.
A machine can be trained to translate the knowledge of an expert into features. The features are all the characteristics of a house, neighborhood, economic environment, etc. that make the price difference. For the expert, it took him probably some years to master the art of estimate the price of a house. His expertise is getting better and better after each sale.
For the machine, it takes millions of data, (i.e., example) to master this art. At the very beginning of its learning, the machine makes a mistake, somehow like the junior salesman. Once the machine sees all the example, it got enough knowledge to make its estimation. At the same time, with incredible accuracy. The machine is also able to adjust its mistake accordingly.
Most of the big company have understood the value of machine learning and holding data. McKinsey have estimated that the value of analytics ranges from $9.5 trillion to $15.4 trillion while $5 to 7 trillion can be attributed to the most advanced AI techniques.
Deep Learning Tutorial for Beginners: Neural Network Classification
What is Deep Learning?
Deep learning is a computer software that mimics the network of neurons in a brain. It is a subset of machine learning and is called deep learning because it makes use of deep neural networks.
Deep learning algorithms are constructed with connected layers.
- The first layer is called the Input Layer
- The last layer is called the Output Layer
- All layers in between are called Hidden Layers. The word deep means the network join neurons in more than two layers.

Each Hidden layer is composed of neurons. The neurons are connected to each other. The neuron will process and then propagate the input signal it receives the layer above it. The strength of the signal given the neuron in the next layer depends on the weight, bias and activation function.
The network consumes large amounts of input data and operates them through multiple layers; the network can learn increasingly complex features of the data at each layer.
In this training, you will learn-
- What is Deep Learning?
- Deep learning Process
- Classification of Neural Networks
- Types of Deep Learning Networks
- Feed-forward neural networks
- Recurrent neural networks (RNNs)
- Convolutional neural networks (CNN)
- Reinforcement Learning
- Examples of deep learning applications
- Why is Deep Learning Important?
- Limitations of deep learning
Deep learning Process
A deep neural network provides state-of-the-art accuracy in many tasks, from object detection to speech recognition. They can learn automatically, without predefined knowledge explicitly coded by the programmers.

To grasp the idea of deep learning, imagine a family, with an infant and parents. The toddler points objects with his little finger and always says the word 'cat.' As its parents are concerned about his education, they keep telling him 'Yes, that is a cat' or 'No, that is not a cat.' The infant persists in pointing objects but becomes more accurate with 'cats.' The little kid, deep down, does not know why he can say it is a cat or not. He has just learned how to hierarchies complex features coming up with a cat by looking at the pet overall and continue to focus on details such as the tails or the nose before to make up his mind.
A neural network works quite the same. Each layer represents a deeper level of knowledge, i.e., the hierarchy of knowledge. A neural network with four layers will learn more complex feature than with that with two layers.
The learning occurs in two phases.
- The first phase consists of applying a nonlinear transformation of the input and create a statistical model as output.
- The second phase aims at improving the model with a mathematical method known as derivative.
The neural network repeats these two phases hundreds to thousands of time until it has reached a tolerable level of accuracy. The repeat of this two-phase is called an iteration.
To give an example, take a look at the motion below, the model is trying to learn how to dance. After 10 minutes of training, the model does not know how to dance, and it looks like a scribble.

After 48 hours of learning, the computer masters the art of dancing.

Classification of Neural Networks
Shallow neural network: The Shallow neural network has only one hidden layer between the input and output.
Deep neural network: Deep neural networks have more than one layer. For instance, Google LeNet model for image recognition counts 22 layers.
Nowadays, deep learning is used in many ways like a driverless car, mobile phone, Google Search Engine, Fraud detection, TV, and so on.
Types of Deep Learning Networks

Feed-forward neural networks
The simplest type of artificial neural network. With this type of architecture, information flows in only one direction, forward. It means, the information's flows starts at the input layer, goes to the "hidden" layers, and end at the output layer. The network
does not have a loop. Information stops at the output layers.
Recurrent neural networks (RNNs)
RNN is a multi-layered neural network that can store information in context nodes, allowing it to learn data sequences and output a number or another sequence. In simple words it an Artificial neural networks whose connections between neurons include loops. RNNs are well suited for processing sequences of inputs.

Example, if the task is to predict the next word in the sentence "Do you want a…………?
- The RNN neurons will receive a signal that point to the start of the sentence.
- The network receives the word "Do" as an input and produces a vector of the number. This vector is fed back to the neuron to provide a memory to the network. This stage helps the network to remember it received "Do" and it received it in the first position.
- The network will similarly proceed to the next words. It takes the word "you" and "want." The state of the neurons is updated upon receiving each word.
- The final stage occurs after receiving the word "a." The neural network will provide a probability for each English word that can be used to complete the sentence. A well-trained RNN probably assigns a high probability to "café," "drink," "burger," etc.
Common uses of RNN
- Help securities traders to generate analytic reports
- Detect abnormalities in the contract of financial statement
- Detect fraudulent credit-card transaction
- Provide a caption for images
- Power chatbots
- The standard uses of RNN occur when the practitioners are working with time-series data or sequences (e.g., audio recordings or text).
Convolutional neural networks (CNN)
CNN is a multi-layered neural network with a unique architecture designed to extract increasingly complex features of the data at each layer to determine the output. CNN's are well suited for perceptual tasks.

CNN is mostly used when there is an unstructured data set (e.g., images) and the practitioners need to extract information from it
For instance, if the task is to predict an image caption:
- The CNN receives an image of let's say a cat, this image, in computer term, is a collection of the pixel. Generally, one layer for the greyscale picture and three layers for a color picture.
- During the feature learning (i.e., hidden layers), the network will identify unique features, for instance, the tail of the cat, the ear, etc.
- When the network thoroughly learned how to recognize a picture, it can provide a probability for each image it knows. The label with the highest probability will become the prediction of the network.
Reinforcement Learning
Reinforcement learning is a subfield of machine learning in which systems are trained by receiving virtual "rewards" or "punishments," essentially learning by trial and error. Google's DeepMind has used reinforcement learning to beat a human champion in the Go games. Reinforcement learning is also used in video games to improve the gaming experience by providing smarter bot.
One of the most famous algorithms are:
- Q-learning
- Deep Q network
- State-Action-Reward-State-Action (SARSA)
- Deep Deterministic Policy Gradient (DDPG)
Examples of deep learning applications
AI in Finance: The financial technology sector has already started using AI to save time, reduce costs, and add value. Deep learning is changing the lending industry by using more robust credit scoring. Credit decision-makers can use AI for robust credit lending applications to achieve faster, more accurate risk assessment, using machine intelligence to factor in the character and capacity of applicants.
Underwrite is a Fintech company providing an AI solution for credit makers company. underwrite.ai uses AI to detect which applicant is more likely to pay back a loan. Their approach radically outperforms traditional methods.
AI in HR: Under Armour, a sportswear company revolutionizes hiring and modernizes the candidate experience with the help of AI. In fact, Under Armour Reduces hiring time for its retail stores by 35%. Under Armour faced a growing popularity interest back in 2012. They had, on average, 30000 resumes a month. Reading all of those applications and begin to start the screening and interview process was taking too long. The lengthy process to get people hired and on-boarded impacted Under Armour's ability to have their retail stores fully staffed, ramped and ready to operate.
At that time, Under Armour had all of the 'must have' HR technology in place such as transactional solutions for sourcing, applying, tracking and onboarding but those tools weren't useful enough. Under armour choose HireVue, an AI provider for HR solution, for both on-demand and live interviews. The results were bluffing; they managed to decrease by 35% the time to fill. In return, the hired higher quality staffs.
AI in Marketing: AI is a valuable tool for customer service management
and personalization challenges. Improved speech recognition in call-center management and call routing as a result of the application of AI techniques allows a more seamless experience for customers.
For example, deep-learning analysis of audio allows systems to assess a customer's emotional tone. If the customer is responding poorly to the AI chatbot, the system can be rerouted the conversation to real, human operators that take over the issue.
Apart from the three examples above, AI is widely used in other sectors/industries.
Why is Deep Learning Important?
Deep learning is a powerful tool to make prediction an actionable result. Deep learning excels in pattern discovery (unsupervised learning) and knowledge-based prediction. Big data is the fuel for deep learning. When both are combined, an organization can reap unprecedented results in term of productivity, sales, management, and innovation.
Deep learning can outperform traditional method. For instance, deep learning algorithms are 41% more accurate than machine learning algorithm in image classification, 27 % more accurate in facial recognition and 25% in voice recognition.
Limitations of deep learning
Data labeling
Most current AI models are trained through "supervised learning." It means that humans must label and categorize the underlying data, which can be a sizable and error-prone chore. For example, companies developing self-driving-car technologies are hiring hundreds of people to manually annotate hours of video feeds from prototype vehicles to help train these systems.
Obtain huge training datasets
It has been shown that simple deep learning techniques like CNN can, in some cases, imitate the knowledge of experts in medicine and other fields. The current wave of machine learning, however, requires training data sets that are not only labeled but also sufficiently broad and universal.
Deep-learning methods required thousands of observation for models to become relatively good at classification tasks and, in some cases, millions for them to perform at the level of humans. Without surprise, deep learning is famous in giant tech companies; they are using big data to accumulate petabytes of data. It allows them to create an impressive and highly accurate deep learning model.
Explain a problem
Large and complex models can be hard to explain, in human terms. For instance, why a particular decision was obtained. It is one reason that acceptance of some AI tools are slow in application areas where interpretability is useful or indeed required.
Furthermore, as the application of AI expands, regulatory requirements could also drive the need for more explainable AI models.
Summary
Deep learning is the new state-of-the-art for artificial intelligence. Deep learning architecture is composed of an input layer, hidden layers, and an output layer. The word deep means there are more than two fully connected layers.
There is a vast amount of neural network, where each architecture is designed to perform a given task. For instance, CNN works very well with pictures, RNN provides impressive results with time series and text analysis.
Deep learning is now active in different fields, from finance to marketing, supply chain, and marketing. Big firms are the first one to use deep learning because they have already a large pool of data. Deep learning requires to have an extensive training dataset.
AI vs Machine Learning vs Deep Learning: What's the Difference?
What is AI?
Artificial intelligence is imparting a cognitive ability to a machine. The benchmark for AI is the human intelligence regarding reasoning, speech, and vision. This benchmark is far off in the future.
AI has three different levels:
- Narrow AI: A artificial intelligence is said to be narrow when the machine can perform a specific task better than a human. The current research of AI is here now
- General AI: An artificial intelligence reaches the general state when it can perform any intellectual task with the same accuracy level as a human would
- Active AI: An AI is active when it can beat humans in many tasks
Early AI systems used pattern matching and expert systems.

In this tutorial, you will learn-
- What is AI?
- What is ML?
- What is Deep Learning?
- Machine Learning Process
- Deep Learning Process
- Automate Feature Extraction using DL
- Difference between Machine Learning and Deep Learning
- When to use ML or DL?
What is ML?
Machine learning is the best tool so far to analyze, understand and identify a pattern in the data. One of the main ideas behind machine learning is that the computer can be trained to automate tasks that would be exhaustive or impossible for a human being. The clear breach from the traditional analysis is that machine learning can take decisions with minimal human intervention.
Machine learning uses data to feed an algorithm that can understand the relationship between the input and the output. When the machine finished learning, it can predict the value or the class of new data point.
What is Deep Learning?
Deep learning is a computer software that mimics the network of neurons in a brain. It is a subset of machine learning and is called deep learning because it makes use of deep neural networks. The machine uses different layers to learn from the data. The depth of the model is represented by the number of layers in the model. Deep learning is the new state of the art in term of AI. In deep learning, the learning phase is done through a neural network. A neural network is an architecture where the layers are stacked on top of each other

Machine Learning Process
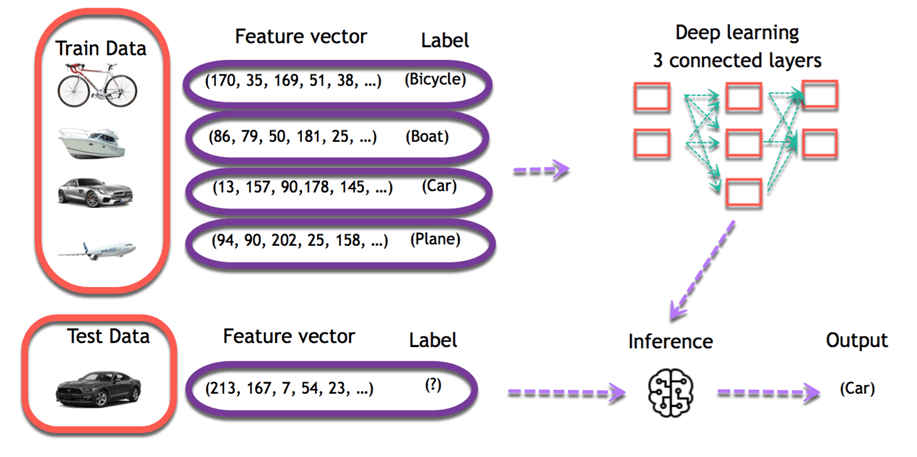
Imagine you are meant to build a program that recognizes objects. To train the model, you will use a classifier. A classifier uses the features of an object to try identifying the class it belongs to.
In the example, the classifier will be trained to detect if the image is a:
- Bicycle
- Boat
- Car
- Plane
The four objects above are the class the classifier has to recognize. To construct a classifier, you need to have some data as input and assigns a label to it. The algorithm will take these data, find a pattern and then classify it in the corresponding class.
This task is called supervised learning. In supervised learning, the training data you feed to the algorithm includes a label.
Training an algorithm requires to follow a few standard steps:
- Collect the data
- Train the classifier
- Make predictions
The first step is necessary, choosing the right data will make the algorithm success or a failure. The data you choose to train the model is called a feature. In the object example, the features are the pixels of the images.
Each image is a row in the data while each pixel is a column. If your image is a 28x28 size, the dataset contains 784 columns (28x28). In the picture below, each picture has been transformed into a feature vector. The label tells the computer what object is in the image.

The objective is to use these training data to classify the type of object. The first step consists of creating the feature columns. Then, the second step involves choosing an algorithm to train the model. When the training is done, the model will predict what picture corresponds to what object.
After that, it is easy to use the model to predict new images. For each new image feeds into the model, the machine will predict the class it belongs to. For example, an entirely new image without a label is going through the model. For a human being, it is trivial to visualize the image as a car. The machine uses its previous knowledge to predict as well the image is a car.
Deep Learning Process
In deep learning, the learning phase is done through a neural network. A neural network is an architecture where the layers are stacked on top of each other.
Consider the same image example above. The training set would be fed to a neural network
Each input goes into a neuron and is multiplied by a weight. The result of the multiplication flows to the next layer and become the input. This process is repeated for each layer of the network. The final layer is named the output layer; it provides an actual value for the regression task and a probability of each class for the classification task. The neural network uses a mathematical algorithm to update the weights of all the neurons. The neural network is fully trained when the value of the weights gives an output close to the reality. For instance, a well-trained neural network can recognize the object on a picture with higher accuracy than the traditional neural net.
Automate Feature Extraction using DL
A dataset can contain a dozen to hundreds of features. The system will learn from the relevance of these features. However, not all features are meaningful for the algorithm. A crucial part of machine learning is to find a relevant set of features to make the system learns something.
One way to perform this part in machine learning is to use feature extraction. Feature extraction combines existing features to create a more relevant set of features. It can be done with PCA, T-SNE or any other dimensionality reduction algorithms.
For example, an image processing, the practitioner needs to extract the feature manually in the image like the eyes, the nose, lips and so on. Those extracted features are feed to the classification model.
Deep learning solves this issue, especially for a convolutional neural network. The first layer of a neural network will learn small details from the picture; the next layers will combine the previous knowledge to make more complex information. In the convolutional neural network, the feature extraction is done with the use of the filter. The network applies a filter to the picture to see if there is a match, i.e., the shape of the feature is identical to a part of the image. If there is a match, the network will use this filter. The process of feature extraction is therefore done automatically.

Difference between Machine Learning and Deep Learning
Machine Learning
|
Deep Learning
| |
Data Dependencies
|
Excellent performances on a small/medium dataset
|
Excellent performance on a big dataset
|
Hardware dependencies
|
Work on a low-end machine.
|
Requires powerful machine, preferably with GPU: DL performs a significant amount of matrix multiplication
|
Feature engineering
|
Need to understand the features that represent the data
|
No need to understand the best feature that represents the data
|
Execution time
|
From few minutes to hours
|
Up to weeks. Neural Network needs to compute a significant number of weights
|
Interpretability
|
Some algorithms are easy to interpret (logistic, decision tree), some are almost impossible (SVM, XGBoost)
|
Difficult to impossible
|
When to use ML or DL?
In the table below, we summarize the difference between machine learning and deep learning.
| Machine learning | Deep learning | |
| Training dataset | Small | Large |
| Choose features | Yes | No |
| Number of algorithms | Many | Few |
| Training time | Short | Long |
With machine learning, you need fewer data to train the algorithm than deep learning. Deep learning requires an extensive and diverse set of data to identify the underlying structure. Besides, machine learning provides a faster-trained model. Most advanced deep learning architecture can take days to a week to train. The advantage of deep learning over machine learning is it is highly accurate. You do not need to understand what features are the best representation of the data; the neural network learned how to select critical features. In machine learning, you need to choose for yourself what features to include in the model.

Summary
Artificial intelligence is imparting a cognitive ability to a machine. Early AI systems used pattern matching and expert systems.
The idea behind machine learning is that the machine can learn without human intervention. The machine needs to find a way to learn how to solve a task given the data.
Deep learning is the breakthrough in the field of artificial intelligence. When there is enough data to train on, deep learning achieves impressive results, especially for image recognition and text translation. The main reason is the feature extraction is done automatically in the different layers of the network.
Supervised Machine Learning: What is, Algorithms, Example
What is Supervised Machine Learning?
In Supervised learning, you train the machine using data which is well "labeled." It means some data is already tagged with the correct answer. It can be compared to learning which takes place in the presence of a supervisor or a teacher.
A supervised learning algorithm learns from labeled training data, helps you to predict outcomes for unforeseen data.
Successfully building, scaling, and deploying accurate supervised machine learning models takes time and technical expertise from a team of highly skilled data scientists. Moreover, Data scientist must rebuild models to make sure the insights given remains true until its data changes.
In this tutorial, you will learn:
- What is Supervised Machine Learning?
- How Supervised Learning Works
- Types of Supervised Machine Learning Algorithms
- Supervised vs. Unsupervised Machine learning techniques
- Challenges in Supervised machine learning
- Advantages of Supervised Learning:
- Disadvantages of Supervised Learning
- Best practices for Supervised Learning
How Supervised Learning Works
For example, you want to train a machine to help you predict how long it will take you to drive home from your workplace. Here, you start by creating a set of labeled data. This data includes
- Weather conditions
- Time of the day
- Holidays
All these details are your inputs. The output is the amount of time it took to drive back home on that specific day.

You instinctively know that if it's raining outside, then it will take you longer to drive home. But the machine needs data and statistics.
Let's see now how you can develop a supervised learning model of this example which help the user to determine the commute time. The first thing you requires to create is a training set. This training set will contain the total commute time and corresponding factors like weather, time, etc. Based on this training set, your machine might see there's a direct relationship between the amount of rain and time you will take to get home.
So, it ascertains that the more it rains, the longer you will be driving to get back to your home. It might also see the connection between the time you leave work and the time you'll be on the road.
The closer you're to 6 p.m. the longer it takes for you to get home. Your machine may find some of the relationships with your labeled data.
This is the start of your Data Model. It begins to impact how rain impacts the way people drive. It also starts to see that more people travel during a particular time of day.
Types of Supervised Machine Learning Algorithms
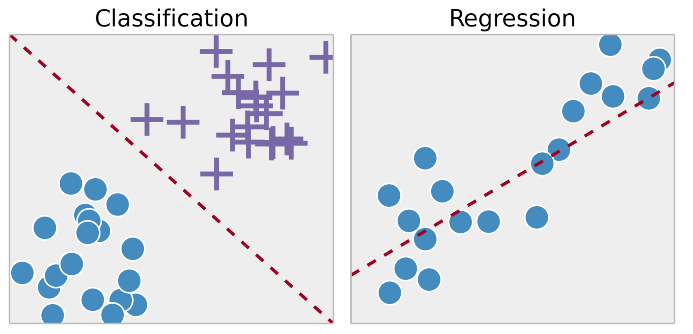
Regression:
Regression technique predicts a single output value using training data.
Example: You can use regression to predict the house price from training data. The input variables will be locality, size of a house, etc.
Strengths: Outputs always have a probabilistic interpretation, and the algorithm can be regularized to avoid overfitting.
Weaknesses: Logistic regression may underperform when there are multiple or non-linear decision boundaries. This method is not flexible, so it does not capture more complex relationships.
Logistic Regression:
Logistic regression method used to estimate discrete values based on given a set of independent variables. It helps you to predicts the probability of occurrence of an event by fitting data to a logit function. Therefore, it is also known as logistic regression. As it predicts the probability, its output value lies between 0 and 1.
Here are a few types of Regression Algorithms
Classification:
Classification means to group the output inside a class. If the algorithm tries to label input into two distinct classes, it is called binary classification. Selecting between more than two classes is referred to as multiclass classification.
Example: Determining whether or not someone will be a defaulter of the loan.
Strengths: Classification tree perform very well in practice
Weaknesses: Unconstrained, individual trees are prone to overfitting.
Here are a few types of Classification Algorithms
Naïve Bayes Classifiers
Naïve Bayesian model (NBN) is easy to build and very useful for large datasets. This method is composed of direct acyclic graphs with one parent and several children. It assumes independence among child nodes separated from their parent.
Decision Trees
Decisions trees classify instance by sorting them based on the feature value. In this method, each mode is the feature of an instance. It should be classified, and every branch represents a value which the node can assume. It is a widely used technique for classification. In this method, classification is a tree which is known as a decision tree.
It helps you to estimate real values (cost of purchasing a car, number of calls, total monthly sales, etc.).
Support Vector Machine
Support vector machine (SVM) is a type of learning algorithm developed in 1990. This method is based on results from statistical learning theory introduced by Vap Nik.
SVM machines are also closely connected to kernel functions which is a central concept for most of the learning tasks. The kernel framework and SVM are used in a variety of fields. It includes multimedia information retrieval, bioinformatics, and pattern recognition.
Supervised vs. Unsupervised Machine learning techniques
| Based On | Supervised machine learning technique | Unsupervised machine learning technique |
| Input Data | Algorithms are trained using labeled data. | Algorithms are used against data which is not labelled |
| Computational Complexity | Supervised learning is a simpler method. | Unsupervised learning is computationally complex |
| Accuracy | Highly accurate and trustworthy method. | Less accurate and trustworthy method. |
Challenges in Supervised machine learning
Here, are challenges faced in supervised machine learning:
- Irrelevant input feature present training data could give inaccurate results
- Data preparation and pre-processing is always a challenge.
- Accuracy suffers when impossible, unlikely, and incomplete values have been inputted as training data
- If the concerned expert is not available, then the other approach is "brute-force." It means you need to think that the right features (input variables) to train the machine on. It could be inaccurate.
Advantages of Supervised Learning:
- Supervised learning allows you to collect data or produce a data output from the previous experience
- Helps you to optimize performance criteria using experience
- Supervised machine learning helps you to solve various types of real-world computation problems.
Disadvantages of Supervised Learning
- Decision boundary might be overtrained if your training set which doesn't have examples that you want to have in a class
- You need to select lots of good examples from each class while you are training the classifier.
- Classifying big data can be a real challenge.
- Training for supervised learning needs a lot of computation time.
Best practices for Supervised Learning
- Before doing anything else, you need to decide what kind of data is to be used as a training set
- You need to decide the structure of the learned function and learning algorithm.
- Gathere corresponding outputs either from human experts or from measurements
Summary
- In Supervised learning, you train the machine using data which is well "labelled."
- You want to train a machine which helps you predict how long it will take you to drive home from your workplace is an example of supervised learning
- Regression and Classification are two types of supervised machine learning techniques.
- Supervised learning is a simpler method while Unsupervised learning is a complex method.
- The biggest challenge in supervised learning is that Irrelevant input feature present training data could give inaccurate results.
- The main advantage of supervised learning is that it allows you to collect data or produce a data output from the previous experience.
- The drawback of this model is that decision boundary might be overstrained if your training set doesn't have examples that you want to have in a class.
- As a best practice of supervise learning, you first need to decide what kind of data should be used as a training set.
Unsupervised Machine Learning: What is, Algorithms, Example
What is Unsupervised Learning?
Unsupervised learning is a machine learning technique, where you do not need to supervise the model. Instead, you need to allow the model to work on its own to discover information. It mainly deals with the unlabelled data.
Unsupervised learning algorithms allows you to perform more complex processing tasks compared to supervised learning. Although, unsupervised learning can be more unpredictable compared with other natural learning methods.
In this tutorial, you will learn:
- What is Unsupervised Learning?
- Example of Unsupervised Machine Learning
- Why Unsupervised Learning?
- Types of Unsupervised Learning
- Clustering
- Clustering Types
- Association
- Supervised vs. Unsupervised Machine Learning
- Applications of unsupervised machine learning
- Disadvantages of Unsupervised Learning
Example of Unsupervised Machine Learning
Let's, take the case of a baby and her family dog.

She knows and identifies this dog. Few weeks later a family friend brings along a dog and tries to play with the baby.

Baby has not seen this dog earlier. But it recognizes many features (2 ears, eyes, walking on 4 legs) are like her pet dog. She identifies the new animal as a dog. This is unsupervised learning, where you are not taught but you learn from the data (in this case data about a dog.) Had this been supervised learning, the family friend would have told the baby that it's a dog.
Why Unsupervised Learning?
Here, are prime reasons for using Unsupervised Learning:
- Unsupervised machine learning finds all kind of unknown patterns in data.
- Unsupervised methods help you to find features which can be useful for categorization.
- It is taken place in real time, so all the input data to be analyzed and labeled in the presence of learners.
- It is easier to get unlabeled data from a computer than labeled data, which needs manual intervention.
Types of Unsupervised Learning
Unsupervised learning problems further grouped into clustering and association problems.
Clustering

Clustering is an important concept when it comes to unsupervised learning. It mainly deals with finding a structure or pattern in a collection of uncategorized data. Clustering algorithms will process your data and find natural clusters(groups) if they exist in the data. You can also modify how many clusters your algorithms should identify. It allows you to adjust the granularity of these groups.
There are different types of clustering you can utilize:
Exclusive (partitioning)
In this clustering method, Data are grouped in such a way that one data can belong to one cluster only.
Example: K-means
Agglomerative
In this clustering technique, every data is a cluster. The iterative unions between the two nearest clusters reduce the number of clusters.
Example: Hierarchical clustering
Overlapping
In this technique, fuzzy sets is used to cluster data. Each point may belong to two or more clusters with separate degrees of membership.
Here, data will be associated with an appropriate membership value. Example: Fuzzy C-Means
Probabilistic
This technique uses probability distribution to create the clusters
Example: Following keywords
- "man's shoe."
- "women's shoe."
- "women's glove."
- "man's glove."
can be clustered into two categories "shoe" and "glove" or "man" and "women."
Clustering Types
- Hierarchical clustering
- K-means clustering
- K-NN (k nearest neighbors)
- Principal Component Analysis
- Singular Value Decomposition
- Independent Component Analysis
Hierarchical Clustering:
Hierarchical clustering is an algorithm which builds a hierarchy of clusters. It begins with all the data which is assigned to a cluster of their own. Here, two close cluster are going to be in the same cluster. This algorithm ends when there is only one cluster left.
K-means Clustering
K means it is an iterative clustering algorithm which helps you to find the highest value for every iteration. Initially, the desired number of clusters are selected. In this clustering method, you need to cluster the data points into k groups. A larger k means smaller groups with more granularity in the same way. A lower k means larger groups with less granularity.
The output of the algorithm is a group of "labels." It assigns data point to one of the k groups. In k-means clustering, each group is defined by creating a centroid for each group. The centroids are like the heart of the cluster, which captures the points closest to them and adds them to the cluster.
K-mean clustering further defines two subgroups:
- Agglomerative clustering
- Dendrogram
Agglomerative clustering:
This type of K-means clustering starts with a fixed number of clusters. It allocates all data into the exact number of clusters. This clustering method does not require the number of clusters K as an input. Agglomeration process starts by forming each data as a single cluster.
This method uses some distance measure, reduces the number of clusters (one in each iteration) by merging process. Lastly, we have one big cluster that contains all the objects.
Dendrogram:
In the Dendrogram clustering method, each level will represent a possible cluster. The height of dendrogram shows the level of similarity between two join clusters. The closer to the bottom of the process they are more similar cluster which is finding of the group from dendrogram which is not natural and mostly subjective.
K- Nearest neighbors
K- nearest neighbour is the simplest of all machine learning classifiers. It differs from other machine learning techniques, in that it doesn't produce a model. It is a simple algorithm which stores all available cases and classifies new instances based on a similarity measure.
It works very well when there is a distance between examples. The learning speed is slow when the training set is large, and the distance calculation is nontrivial.
Principal Components Analysis:
In case you want a higher-dimensional space. You need to select a basis for that space and only the 200 most important scores of that basis. This base is known as a principal component. The subset you select constitute is a new space which is small in size compared to original space. It maintains as much of the complexity of data as possible.
Association
Association rules allow you to establish associations amongst data objects inside large databases. This unsupervised technique is about discovering interesting relationships between variables in large databases. For example, people that buy a new home most likely to buy new furniture.
Other Examples:
- A subgroup of cancer patients grouped by their gene expression measurements
- Groups of shopper based on their browsing and purchasing histories
- Movie group by the rating given by movies viewers
Supervised vs. Unsupervised Machine Learning
| Parameters | Supervised machine learning technique | Unsupervised machine learning technique |
| Input Data | Algorithms are trained using labeled data. | Algorithms are used against data which is not labelled |
| Computational Complexity | Supervised learning is a simpler method. | Unsupervised learning is computationally complex |
| Accuracy | Highly accurate and trustworthy method. | Less accurate and trustworthy method. |
Applications of unsupervised machine learning
Some applications of unsupervised machine learning techniques are:
- Clustering automatically split the dataset into groups base on their similarities
- Anomaly detection can discover unusual data points in your dataset. It is useful for finding fraudulent transactions
- Association mining identifies sets of items which often occur together in your dataset
- Latent variable models are widely used for data preprocessing. Like reducing the number of features in a dataset or decomposing the dataset into multiple components
Disadvantages of Unsupervised Learning
- You cannot get precise information regarding data sorting, and the output as data used in unsupervised learning is labeled and not known
- Less accuracy of the results is because the input data is not known and not labeled by people in advance. This means that the machine requires to do this itself.
- The spectral classes do not always correspond to informational classes.
- The user needs to spend time interpreting and label the classes which follow that classification.
- Spectral properties of classes can also change over time so you can't have the same class information while moving from one image to another.
Summary
- Unsupervised learning is a machine learning technique, where you do not need to supervise the model.
- Unsupervised machine learning helps you to finds all kind of unknown patterns in data.
- Clustering and Association are two types of Unsupervised learning.
- Four types of clustering methods are 1) Exclusive 2) Agglomerative 3) Overlapping 4) Probabilistic.
- Important clustering types are: 1)Hierarchical clustering 2) K-means clustering 3) K-NN 4) Principal Component Analysis 5) Singular Value Decomposition 6) Independent Component Analysis.
- Association rules allow you to establish associations amongst data objects inside large databases.
- In Supervised learning, Algorithms are trained using labelled data while in Unsupervised learning Algorithms are used against data which is not labelled.
- Anomaly detection can discover important data points in your dataset which is useful for finding fraudulent transactions.
- The biggest drawback of Unsupervised learning is that you cannot get precise information regarding data sorting.
Supervised vs Unsupervised Learning: Key Differences
What is Supervised Machine Learning?
In Supervised learning, you train the machine using data which is well "labeled." It means some data is already tagged with the correct answer. It can be compared to learning which takes place in the presence of a supervisor or a teacher.A supervised learning algorithm learns from labeled training data, helps you to predict outcomes for unforeseen data. Successfully building, scaling, and deploying accurate supervised machine learning Data science model takes time and technical expertise from a team of highly skilled data scientists. Moreover, Data scientist must rebuild models to make sure the insights given remains true until its data changes.- In this tutorial, you will learn
- What is Supervised Machine Learning?
- What is Unsupervised Learning?
- Why Supervised Learning?
- Why Unsupervised Learning?
- How Supervised Learning works?
- How Unsupervised Learning works?
- Types of Supervised Machine Learning Techniques
- Types of Unsupervised Machine Learning Techniques
- Supervised vs. Unsupervised Learning
What is Unsupervised Learning?
Unsupervised learning is a machine learning technique, where you do not need to supervise the model. Instead, you need to allow the model to work on its own to discover information. It mainly deals with the unlabelled data.Unsupervised learning algorithms allow you to perform more complex processing tasks compared to supervised learning. Although, unsupervised learning can be more unpredictable compared with other natural learning deep learning and reinforcement learning methods.Why Supervised Learning?
- Supervised learning allows you to collect data or produce a data output from the previous experience.
- Helps you to optimize performance criteria using experience
- Supervised machine learning helps you to solve various types of real-world computation problems.
Why Unsupervised Learning?
Here, are prime reasons for using Unsupervised Learning:- Unsupervised machine learning finds all kind of unknown patterns in data.
- Unsupervised methods help you to find features which can be useful for categorization.
- It is taken place in real time, so all the input data to be analyzed and labeled in the presence of learners.
- It is easier to get unlabeled data from a computer than labeled data, which needs manual intervention.
How Supervised Learning works?
For example, you want to train a machine to help you predict how long it will take you to drive home from your workplace. Here, you start by creating a set of labeled data. This data includes- Weather conditions
- Time of the day
- Holidays
All these details are your inputs. The output is the amount of time it took to drive back home on that specific day.You instinctively know that if it's raining outside, then it will take you longer to drive home. But the machine needs data and statistics.Let's see now how you can develop a supervised learning model of this example which help the user to determine the commute time. The first thing you requires to create is a training data set. This training set will contain the total commute time and corresponding factors like weather, time, etc. Based on this training set, your machine might see there's a direct relationship between the amount of rain and time you will take to get home.So, it ascertains that the more it rains, the longer you will be driving to get back to your home. It might also see the connection between the time you leave work and the time you'll be on the road.The closer you're to 6 p.m. the longer time it takes for you to get home. Your machine may find some of the relationships with your labeled data.This is the start of your Data Model. It begins to impact how rain impacts the way people drive. It also starts to see that more people travel during a particular time of day.How Unsupervised Learning works?
Let's, take the case of a baby and her family dog.She knows and identifies this dog. A few weeks later a family friend brings along a dog and tries to play with the baby.Baby has not seen this dog earlier. But it recognizes many features (2 ears, eyes, walking on 4 legs) are like her pet dog. She identifies a new animal like a dog. This is unsupervised learning, where you are not taught but you learn from the data (in this case data about a dog.) Had this been supervised learning, the family friend would have told the baby that it's a dog.Types of Supervised Machine Learning Techniques
Regression:
Regression technique predicts a single output value using training data.Example: You can use regression to predict the house price from training data. The input variables will be locality, size of a house, etc.Classification:
Classification means to group the output inside a class. If the algorithm tries to label input into two distinct classes, it is called binary classification. Selecting between more than two classes is referred to as multiclass classification.Example: Determining whether or not someone will be a defaulter of the loan.Strengths: Outputs always have a probabilistic interpretation, and the algorithm can be regularized to avoid overfitting.Weaknesses: Logistic regression may underperform when there are multiple or non-linear decision boundaries. This method is not flexible, so it does not capture more complex relationships.Types of Unsupervised Machine Learning Techniques
Unsupervised learning problems further grouped into clustering and association problems.Clustering
Clustering is an important concept when it comes to unsupervised learning. It mainly deals with finding a structure or pattern in a collection of uncategorized data. Clustering algorithms will process your data and find natural clusters(groups) if they exist in the data. You can also modify how many clusters your algorithms should identify. It allows you to adjust the granularity of these groups.Association
Association rules allow you to establish associations amongst data objects inside large databases. This unsupervised technique is about discovering exciting relationships between variables in large databases. For example, people that buy a new home most likely to buy new furniture.Other Examples:- A subgroup of cancer patients grouped by their gene expression measurements
- Groups of shopper based on their browsing and purchasing histories
- Movie group by the rating given by movies viewers
Supervised vs. Unsupervised Learning

Parameters Supervised machine learning technique Unsupervised machine learning technique Process In a supervised learning model, input and output variables will be given. In unsupervised learning model, only input data will be given Input Data Algorithms are trained using labeled data. Algorithms are used against data which is not labeled Algorithms Used Support vector machine, Neural network, Linear and logistics regression, random forest, and Classification trees. Unsupervised algorithms can be divided into different categories: like Cluster algorithms, K-means, Hierarchical clustering, etc. Computational Complexity Supervised learning is a simpler method. Unsupervised learning is computationally complex Use of Data Supervised learning model uses training data to learn a link between the input and the outputs. Unsupervised learning does not use output data. Accuracy of Results Highly accurate and trustworthy method. Less accurate and trustworthy method. Real Time Learning Learning method takes place offline. Learning method takes place in real time. Number of Classes Number of classes is known. Number of classes is not known. Main Drawback Classifying big data can be a real challenge in Supervised Learning. You cannot get precise information regarding data sorting, and the output as data used in unsupervised learning is labeled and not known. Summary
- In Supervised learning, you train the machine using data which is well "labeled."
- Unsupervised learning is a machine learning technique, where you do not need to supervise the model.
- Supervised learning allows you to collect data or produce a data output from the previous experience.
- Unsupervised machine learning helps you to finds all kind of unknown patterns in data.
- For example, you will able to determine the time taken to reach back come base on weather condition, Times of the day and holiday.
- For example, Baby can identify other dogs based on past supervised learning.
- Regression and Classification are two types of supervised machine learning techniques.
- Clustering and Association are two types of Unsupervised learning.
- In a supervised learning model, input and output variables will be given while with unsupervised learning model, only input data will be given.
Back Propagation Neural Network: Explained With Simple Example
Before we learn Backpropagation, let's understand:
What is Artificial Neural Networks?
A neural network is a group of connected I/O units where each connection has a weight associated with its computer programs. It helps you to build predictive models from large databases. This model builds upon the human nervous system. It helps you to conduct image understanding, human learning, computer speech, etc.
What is Backpropagation?
Back-propagation is the essence of neural net training. It is the method of fine-tuning the weights of a neural net based on the error rate obtained in the previous epoch (i.e., iteration). Proper tuning of the weights allows you to reduce error rates and to make the model reliable by increasing its generalization.
Backpropagation is a short form for "backward propagation of errors." It is a standard method of training artificial neural networks. This method helps to calculate the gradient of a loss function with respects to all the weights in the network.
In this tutorial, you will learn:
- What is Artificial Neural Networks?
- What is Backpropagation?
- How Backpropagation Works
- Why We Need Backpropagation?
- What is a Feed Forward Network?
- Types of Backpropagation Networks
- History of Backpropagation
- Backpropagation Key Points
- Best practice Backpropagation
- Disadvantages of using Backpropagation
How Backpropagation Works: Simple Algorithm
Consider the following diagram
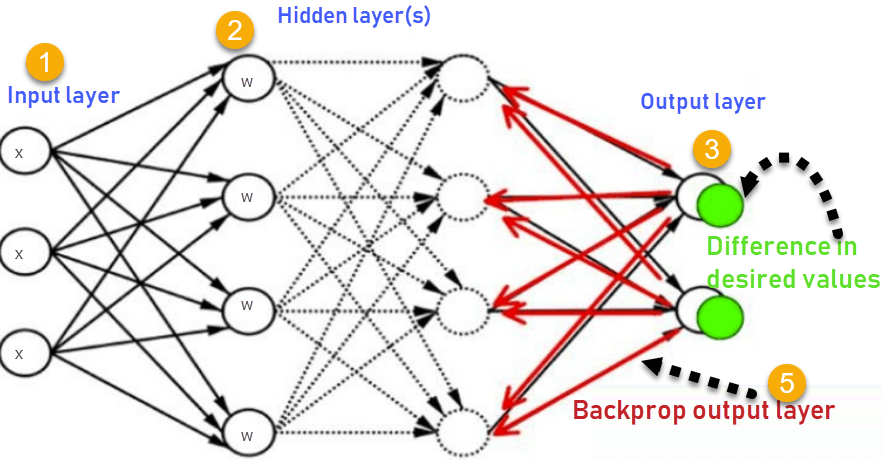
- Inputs X, arrive through the preconnected path
- Input is modeled using real weights W. The weights are usually randomly selected.
- Calculate the output for every neuron from the input layer, to the hidden layers, to the output layer.
- Calculate the error in the outputs
ErrorB= Actual Output – Desired Output
- Travel back from the output layer to the hidden layer to adjust the weights such that the error is decreased.
Keep repeating the process until the desired output is achieved
Why We Need Backpropagation?
Most prominent advantages of Backpropagation are:
- Backpropagation is fast, simple and easy to program
- It has no parameters to tune apart from the numbers of input
- It is a flexible method as it does not require prior knowledge about the network
- It is a standard method that generally works well
- It does not need any special mention of the features of the function to be learned.
What is a Feed Forward Network?
A feedforward neural network is an artificial neural network where the nodes never form a cycle. This kind of neural network has an input layer, hidden layers, and an output layer. It is the first and simplest type of artificial neural network.
Types of Backpropagation Networks
Two Types of Backpropagation Networks are:
- Static Back-propagation
- Recurrent Backpropagation
Static back-propagation:
It is one kind of backpropagation network which produces a mapping of a static input for static output. It is useful to solve static classification issues like optical character recognition.
Recurrent Backpropagation:
Recurrent backpropagation is fed forward until a fixed value is achieved. After that, the error is computed and propagated backward.
The main difference between both of these methods is: that the mapping is rapid in static back-propagation while it is nonstatic in recurrent backpropagation.
History of Backpropagation
- In 1961, the basics concept of continuous backpropagation were derived in the context of control theory by J. Kelly, Henry Arthur, and E. Bryson.
- In 1969, Bryson and Ho gave a multi-stage dynamic system optimization method.
- In 1974, Werbos stated the possibility of applying this principle in an artificial neural network.
- In 1982, Hopfield brought his idea of a neural network.
- In 1986, by the effort of David E. Rumelhart, Geoffrey E. Hinton, Ronald J. Williams, backpropagation gained recognition.
- In 1993, Wan was the first person to win an international pattern recognition contest with the help of the backpropagation method.
Backpropagation Key Points
- Simplifies the network structure by elements weighted links that have the least effect on the trained network
- You need to study a group of input and activation values to develop the relationship between the input and hidden unit layers.
- It helps to assess the impact that a given input variable has on a network output. The knowledge gained from this analysis should be represented in rules.
- Backpropagation is especially useful for deep neural networks working on error-prone projects, such as image or speech recognition.
- Backpropagation takes advantage of the chain and power rules allows backpropagation to function with any number of outputs.
Best practice Backpropagation
Backpropagation can be explained with the help of "Shoe Lace" analogy
Too little tension =
- Not enough constraining and very loose
Too much tension =
- Too much constraint (overtraining)
- Taking too much time (relatively slow process)
- Higher likelihood of breaking
Pulling one less more than other =
- Discomfort (bias)
Disadvantages of using Backpropagation
- The actual performance of backpropagation on a specific problem is dependent on the input data.
- Backpropagation can be quite sensitive to noisy data
- You need to use the matrix-based approach for backpropagation instead of mini-batch.
Summary
- A neural network is a group of connected it I/O units where each connection has a weight associated with its computer programs.
- Backpropagation is a short form for "backward propagation of errors." It is a standard method of training artificial neural networks
- Backpropagation is fast, simple and easy to program
- A feedforward neural network is an artificial neural network.
- Two Types of Backpropagation Networks are 1)Static Back-propagation 2) Recurrent Backpropagation
- In 1961, the basics concept of continuous backpropagation were derived in the context of control theory by J. Kelly, Henry Arthur, and E. Bryson.
- Backpropagation simplifies the network structure by removing weighted links that have a minimal effect on the trained network.
- It is especially useful for deep neural networks working on error-prone projects, such as image or speech recognition.
- The biggest drawback of the Backpropagation is that it can be sensitive for noisy data.
- TensorFlow vs Theano vs Torch vs Keras: Deep Learning Libraries
- Artificial intelligence is growing in popularity since 2016 with, 20% of the big companies using AI in their businesses (McKinsey report, 2018). As per the same report AI can create substantial value across industries. In banking, for instance, the potential of AI is estimated at $ 300 billion, in retail the number skyrocket to $ 600 billion.To unlock the potential value of AI, companies must choose the right deep learning framework. In this tutorial, you will learn about the different libraries available to carry out deep learning tasks. Some libraries have been around for years while new library like TensorFlow has come to light in recent years.
8 Best Deep learning Libraries /Framework
In this list, we will compare the top Deep learning frameworks. All of them are open source and popular in the data scientist community. We will also compare popular ML as a service providersTorchTorch is an old open source machine learning library. It is first released was 15 years ago. It is primary programming languages is LUA, but has an implementation in C. Torch supports a vast library for machine learning algorithms, including deep learning. It supports CUDA implementation for parallel computation.Torch is used by most of the leading labs such as Facebook, Google, Twitter, Nvidia, and so on. Torch has a library in Python names Pytorch.Infer.netInfer.net is developed and maintained by Microsoft. Infer.net is a library with a primary focus on the Bayesian statistic. Infer.net is designed to offer practitioners state-of-the-art algorithms for probabilistic modeling. The library contains analytical tools such as Bayesian analysis, hidden Markov chain, clustering.KerasKeras is a Python framework for deep learning. It is a convenient library to construct any deep learning algorithm. The advantage of Keras is that it uses the same Python code to run on CPU or GPU. Besides, the coding environment is pure and allows for training state-of-the-art algorithm for computer vision, text recognition among other.Keras has been developed by François Chollet, a researcher at Google. Keras is used in prominent organizations like CERN, Yelp, Square or Google, Netflix, and Uber. TheanoTheano is deep learning library developed by the Université de Montréal in 2007. It offers fast computation and can be run on both CPU and GPU. Theano has been developed to train deep neural network algorithms.
TheanoTheano is deep learning library developed by the Université de Montréal in 2007. It offers fast computation and can be run on both CPU and GPU. Theano has been developed to train deep neural network algorithms.MICROSOFT COGNITIVE TOOLKIT(CNTK)
Microsoft toolkit, previously know as CNTK, is a deep learning library developed by Microsoft. According to Microsoft, the library is among the fastest on the market. Microsoft toolkit is an open-source library, although Microsoft is using it extensively for its product like Skype, Cortana, Bing, and Xbox. The toolkit is available both in Python and C++.MXNetMXnet is a recent deep learning library. It is accessible with multiple programming languages including C++, Julia, Python and R. MXNet can be configured to work on both CPU and GPU. MXNet includes state-of-the-art deep learning architecture such as Convolutional Neural Network and Long Short-Term Memory. MXNet is build to work in harmony with dynamic cloud infrastructure. The main user of MXNet is AmazonCaffeCaffe is a library built by Yangqing Jia when he was a PhD student at Berkeley. Caffe is written in C++ and can perform computation on both CPU and GPU. The primary uses of Caffe is Convolutional Neural Network. Although, In 2017, Facebook extended Caffe with more deep learning architecture, including Recurrent Neural Network. caffe is used by academics and startups but also some large companies like Yahoo!.TensorFlowTensorFlow is Google open source project. TensorFlow is the most famous deep learning library these days. It was released to the public in late 2015 TensorFlow is developed in C++ and has convenient Python API, although C++ APIs are also available. Prominent companies like Airbus, Google, IBM and so on are using TensorFlow to produce deep learning algorithms.
TensorFlow is developed in C++ and has convenient Python API, although C++ APIs are also available. Prominent companies like Airbus, Google, IBM and so on are using TensorFlow to produce deep learning algorithms.TensorFlow Vs Theano Vs Torch Vs Keras Vs infer.net Vs CNTK Vs MXNet Vs Caffe: Key Differences
Library Platform Written in Cuda support Parallel Execution Has trained models RNN CNN Torch Linux, MacOS, Windows Lua Yes Yes Yes Yes Yes Infer.Net Linux, MacOS, Windows Visual Studio No No No No No Keras Linux, MacOS, Windows Python Yes Yes Yes Yes Yes Theano Cross-platform Python Yes Yes Yes Yes Yes TensorFlow Linux, MacOS, Windows, Android C++, Python, CUDA Yes Yes Yes Yes Yes MICROSOFT COGNITIVE TOOLKIT Linux, Windows, Mac with Docker C++ Yes Yes Yes Yes Yes Caffe Linux, MacOS, Windows C++ Yes Yes Yes Yes Yes MXNet Linux, Windows, MacOs, Android, iOS, Javascript C++ Yes Yes Yes Yes Yes Verdict:TensorFlow is the best library of all because it is built to be accessible for everyone. Tensorflow library incorporates different API to built at scale deep learning architecture like CNN or RNN. TensorFlow is based on graph computation, it allows the developer to visualize the construction of the neural network with Tensorboad. This tool is helpful to debug the program. Finally, Tensorflow is built to be deployed at scale. It runs on CPU and GPU.Tensorflow attracts the largest popularity on GitHub compare to the other deep learning framework.Comparing Machine Learning as a Service
Following are 4 popular DL as a service providersGoogle Cloud ML
Google provides for developer pre-trained model available in Cloud AutoML. This solution exists for a developer without a strong background in machine learning. Developers can use state-of-the-art Google's pre-trained model on their data. It allows any developers to train and evaluate any model in just a few minutes.Google currently provides a REST API for computer vision, speech recognition, translation, and NLP. Using Google Cloud, you can train a machine learning framework build on TensorFlow, Scikit-learn, XGBoost or Keras. Google Cloud machine learning will train the models across its cloud.The advantage to use Google cloud computing is the simplicity to deploy machine learning into production. There is no need to set up Docker container. Besides, the cloud takes care of the infrastructure. It knows how to allocate resources with CPUs, GPUs, and TPUs. It makes the training faster with paralleled computation.
Using Google Cloud, you can train a machine learning framework build on TensorFlow, Scikit-learn, XGBoost or Keras. Google Cloud machine learning will train the models across its cloud.The advantage to use Google cloud computing is the simplicity to deploy machine learning into production. There is no need to set up Docker container. Besides, the cloud takes care of the infrastructure. It knows how to allocate resources with CPUs, GPUs, and TPUs. It makes the training faster with paralleled computation.AWS SageMaker
A major competitor to Google Cloud is Amazon cloud, AWS. Amazon has developed Amazon SageMaker to allow data scientists and developers to build, train and bring into production any machine learning models.SageMaker is available in a Jupyter Notebook and includes the most used machine learning library, TensorFlow, MXNet, Scikit-learn amongst others. Programs written with SageMaker are automatically run in the Docker containers. Amazon handles the resource allocation to optimize the training and deployment. Amazon provides API to the developers in order to add intelligence to their applications. In some occasion, there is no need to reinventing-the-wheel by building from scratch new models while there are powerful pre-trained models in the cloud. Amazon provides API services for computer vision, conversational chatbots and language services:The three major available API are:
Amazon provides API to the developers in order to add intelligence to their applications. In some occasion, there is no need to reinventing-the-wheel by building from scratch new models while there are powerful pre-trained models in the cloud. Amazon provides API services for computer vision, conversational chatbots and language services:The three major available API are:- Amazon Rekognition: provides image and video recognition to an app
- Amazon Comprehend: Perform text mining and neural language processing to, for instance, automatize the process of checking the legality of financial document
- Amazon Lex: Add chatbot to an app
Azure Machine Learning Studio
Probably one of the friendliest approaches to machine learning is Azure Machine Learning Studio. The significant advantage of this solution is that no prior programming knowledge is required.Microsoft Azure Machine Learning Studio is a drag-and-drop collaborative tool to create, train, evaluate and deploy machine learning solution. The model can be efficiently deployed as web services and used in several apps like Excel.Azure Machine learning interface is interactive, allowing the user to build a model just by dragging and dropping elements quickly. When the model is ready, the developer can save it and push it to Azure Gallery or Azure Marketplace.Azure Machine learning can be integrated into R or Python their custom built-in package.
When the model is ready, the developer can save it and push it to Azure Gallery or Azure Marketplace.Azure Machine learning can be integrated into R or Python their custom built-in package.IBM Watson ML
Watson studio can simplify the data projects with a streamlined process that allows extracting value and insights from the data to help the business to get smarter and faster. Watson studio delivers an easy-to-use collaborative data science and machine learning environment for building and training models, preparing and analyzing data, and sharing insights all in one place. Watson Studio is easy to use with a drag-and-drop code. Watson studio supports some of the most popular frameworks like Tensorflow, Keras, Pytorch, Caffe and can deploy a deep learning algorithm on to the latest GPUs from Nvidia to help accelerate modeling.
Watson studio supports some of the most popular frameworks like Tensorflow, Keras, Pytorch, Caffe and can deploy a deep learning algorithm on to the latest GPUs from Nvidia to help accelerate modeling.Verdict:
In our point of view, Google cloud solution is the one that is the most recommended. Google cloud solution provides lower prices the AWS by at least 30% for data storage and machine learning solution. Google is doing an excellent job to democratize AI. It has developed an open source language, TensorFlow, optimized data warehouse connection, provides tremendous tools from data visualization, data analysis to machine learning. Besides, Google Console is ergonomic and much more comprehensive than AWS or Windows.
Fuzzy Logic Tutorial: What is, Application & Example
What Is Fuzzy Logic?
The term fuzzy mean things which are not very clear or vague. In real life, we may come across a situation where we can't decide whether the statement is true or false. At that time, fuzzy logic offers very valuable flexibility for reasoning. We can also consider the uncertainties of any situation.
Fuzzy logic algorithm helps to solve a problem after considering all available data. Then it takes the best possible decision for the given the input. The FL method imitates the way of decision making in a human which consider all the possibilities between digital values T and F.
In this tutorial, you will learn
- What Is Fuzzy Logic?
- History of Fuzzy Logic
- Characteristics of Fuzzy Logic
- When not to use fuzzy logic
- Fuzzy Logic Architecture
- Fuzzy Logic vs. Probability
- Crisp vs. Fuzzy
- Classical Set vs. Fuzzy set Theory
- Fuzzy Logic Examples
- Application Areas of Fuzzy Logic
- Advantages of Fuzzy Logic System
- Disadvantages of Fuzzy Logic Systems
History of Fuzzy Logic
Although, the concept of fuzzy logic had been studied since the 1920's. The term fuzzy logic was first used with 1965 by Lotfi Zadeh a professor of UC Berkeley in California. He observed that conventional computer logic was not capable of manipulating data representing subjective or unclear human ideas.
Fuzzy logic has been applied to various fields, from control theory to AI. It was designed to allow the computer to determine the distinctions among data which is neither true nor false. Something similar to the process of human reasoning. Like Little dark, Some brightness, etc.
Characteristics of Fuzzy Logic
Here, are some important characteristics of fuzzy logic:
- Flexible and easy to implement machine learning technique
- Helps you to mimic the logic of human thought
- Logic may have two values which represent two possible solutions
- Highly suitable method for uncertain or approximate reasoning
- Fuzzy logic views inference as a process of propagating elastic constraints
- Fuzzy logic allows you to build nonlinear functions of arbitrary complexity.
- Fuzzy logic should be built with the complete guidance of experts
When not to use fuzzy logic
However, fuzzy logic is never a cure for all. Therefore, it is equally important to understand that where we should not use fuzzy logic.
Here, are certain situations when you better not use Fuzzy Logic:
- If you don't find it convenient to map an input space to an output space
- Fuzzy logic should not be used when you can use common sense
- Many controllers can do the fine job without the use of fuzzy logic
Fuzzy Logic Architecture
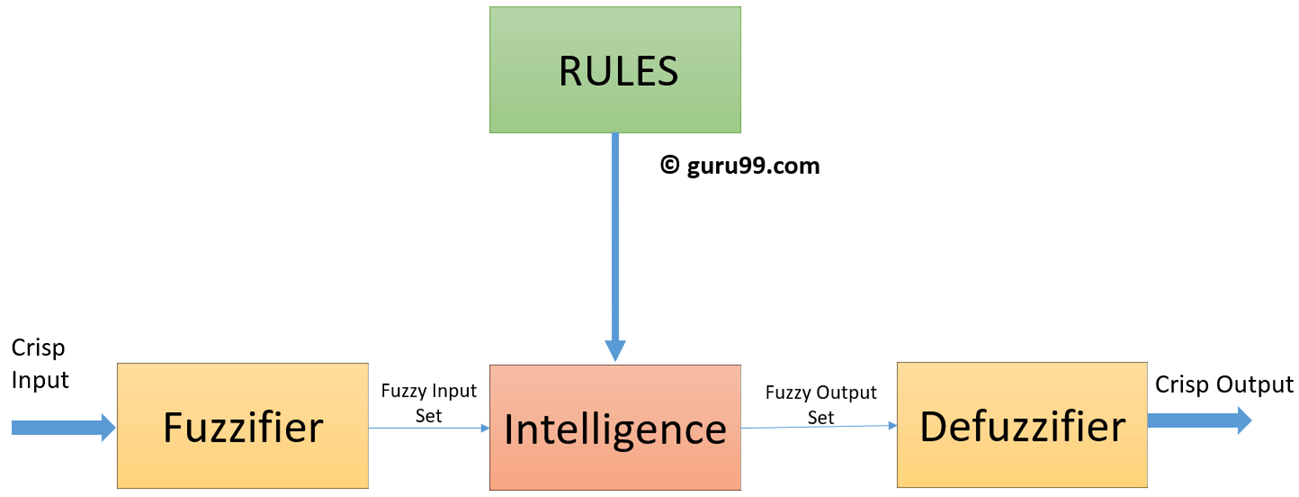
Fuzzy Logic architecture has four main parts as shown in the diagram:
Rule Base:
It contains all the rules and the if-then conditions offered by the experts to control the decision-making system. The recent update in fuzzy theory provides various methods for the design and tuning of fuzzy controllers. This updates significantly reduce the number of the fuzzy set of rules.
Fuzzification:
Fuzzification step helps to convert inputs. It allows you to convert, crisp numbers into fuzzy sets. Crisp inputs measured by sensors and passed into the control system for further processing. Like Room temperature, pressure, etc.
Inference Engine:
It helps you to determines the degree of match between fuzzy input and the rules. Based on the % match, it determines which rules need implment according to the given input field. After this, the applied rules are combined to develop the control actions.
Defuzzification:
At last the Defuzzification process is performed to convert the fuzzy sets into a crisp value. There are many types of techniques available, so you need to select it which is best suited when it is used with an expert system.
Fuzzy Logic vs. Probability
| Fuzzy Logic | Probability |
| Fuzzy: Tom's degree of membership within the set of old people is 0.90. | Probability: There is a 90% chance that Tom is old. |
| Fuzzy logic takes truth degrees as a mathematical basis on the model of the vagueness phenomenon. | Probability is a mathematical model of ignorance. |
Crisp vs. Fuzzy
| Crisp | Fuzzy |
| It has strict boundary T or F | Fuzzy boundary with a degree of membership |
| Some crisp time set can be fuzzy | It can't be crisp |
| True/False {0,1} | Membership values on [0,1] |
| In Crisp logic law of Excluded Middle and Non- Contradiction may or may not hold | In the fuzzy logic law of Excluded Middle and Non- Contradiction hold |
Classical Set vs. Fuzzy set Theory
| Classical Set | Fuzzy Set Theory |
| Classes of objects with sharp boundaries. | Classes of objects do not have sharp boundaries. |
| A classical set is defined by crisp boundaries, i.e., there is clarity about the location of the set boundaries. | A fuzzy set always has ambiguous boundaries, i.e., there may be uncertainty about the location of the set boundaries. |
| Widely used in digital system design | Used only in fuzzy controllers. |
Fuzzy Logic Examples
See the below-given diagram. It shows that in fuzzy systems, the values are denoted by a 0 to 1 number. In this example, 1.0 means absolute truth and 0.0 means absolute falseness.
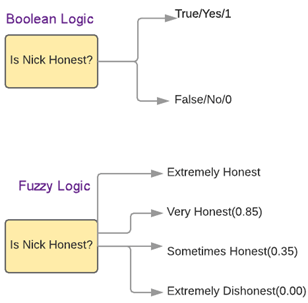
Application Areas of Fuzzy Logic
The Blow given table shows how famous companies using fuzzy logic in their products.
| Product | Company | Fuzzy Logic |
| Anti-lock brakes | Nissan | Use fuzzy logic to controls brakes in hazardous cases depend on car speed, acceleration, wheel speed, and acceleration |
| Auto transmission | NOK/Nissan | Fuzzy logic is used to control the fuel injection and ignition based on throttle setting, cooling water temperature, RPM, etc. |
| Auto engine | Honda, Nissan | Use to select geat based on engine load, driving style, and road conditions. |
| Copy machine | Canon | Using for adjusting drum voltage based on picture density, humidity, and temperature. |
| Cruise control | Nissan, Isuzu, Mitsubishi | Use it to adjusts throttle setting to set car speed and acceleration |
| Dishwasher | Matsushita | Use for adjusting the cleaning cycle, rinse and wash strategies based depend upon the number of dishes and the amount of food served on the dishes. |
| Elevator control | Fujitec, Mitsubishi Electric, Toshiba | Use it to reduce waiting for time-based on passenger traffic |
| Golf diagnostic system | Maruman Golf | Selects golf club based on golfer's swing and physique. |
| Fitness management | Omron | Fuzzy rules implied by them to check the fitness of their employees. |
| Kiln control | Nippon Steel | Mixes cement |
| Microwave oven | Mitsubishi Chemical | Sets lunes power and cooking strategy |
| Palmtop computer | Hitachi, Sharp, Sanyo, Toshiba | Recognizes handwritten Kanji characters |
| Plasma etching | Mitsubishi Electric | Sets etch time and strategy |
Advantages of Fuzzy Logic System
- The structure of Fuzzy Logic Systems is easy and understandable
- Fuzzy logic is widely used for commercial and practical purposes
- It helps you to control machines and consumer products
- It may not offer accurate reasoning, but the only acceptable reasoning
- It helps you to deal with the uncertainty in engineering
- Mostly robust as no precise inputs required
- It can be programmed to in the situation when feedback sensor stops working
- It can easily be modified to improve or alter system performance
- inexpensive sensors can be used which helps you to keep the overall system cost and complexity low
- It provides a most effective solution to complex issues
Disadvantages of Fuzzy Logic Systems
- Fuzzy logic is not always accurate, so The results are perceived based on assumption, so it may not be widely accepted.
- Fuzzy systems don't have the capability of machine learning as-well-as neural network type pattern recognition
- Validation and Verification of a fuzzy knowledge-based system needs extensive testing with hardware
- Setting exact, fuzzy rules and, membership functions is a difficult task
- Some fuzzy time logic is confused with probability theory and the terms
Summary
- The term fuzzy mean things which are not very clear or vague
- The term fuzzy logic was first used with 1965 by Lotfi Zadeh a professor of UC Berkeley in California
- Fuzzy logic is a flexible and easy to implement machine learning technique
- Fuzzy logic should not be used when you can use common sense
- Fuzzy Logic architecture has four main parts 1) Rule Basse 2) Fuzzification 3) Inference Engine 4) Defuzzification
- Fuzzy logic takes truth degrees as a mathematical basis on the model of the vagueness while probability is a mathematical model of ignorance
- Crisp set has strict boundary T or F while Fuzzy boundary with a degree of membership
- A classical set is widely used in digital system design while fuzzy set Used only in fuzzy controllers
- Auto transmission, Fitness management, Golf diagnostic system, Dishwasher, Copy machine are some applications areas of fuzzy logic
Confusion Matrix in Machine Learning with EXAMPLE
What is Confusion Matrix?
A confusion matrix is a performance measurement technique for Machine learning classification. It is a kind of table which helps you to the know the performance of the classification model on a set of test data for that the true values are known. The term confusion matrix itself is very simple, but its related terminology can be a little confusing. Here, some simple explanation is given for this technique.
In this tutorial, you will learn,
- What is Confusion matrix?
- Four outcomes of the confusion matrix
- Example of Confusion matrix:
- How to Calculate a Confusion Matrix
- Other Important Terms using a Confusion matrix
- Why you need Confusion matrix?
Four outcomes of the confusion matrix
The confusion matrix visualizes the accuracy of a classifier by comparing the actual and predicted classes. The binary confusion matrix is composed of squares:

- TP: True Positive: Predicted values correctly predicted as actual positive
- FP: Predicted values incorrectly predicted an actual positive. i.e., Negative values predicted as positive
- FN: False Negative: Positive values predicted as negative
- TN: True Negative: Predicted values correctly predicted as an actual negative
You can compute the accuracy test from the confusion matrix:

Example of Confusion Matrix:
Confusion Matrix is a useful machine learning method which allows you to measure Recall, Precision, Accuracy, and AUC-ROC curve. Below given is an example to know the terms True Positive, True Negative, False Negative, and True Negative.
True Positive:
You projected positive and its turn out to be true. For example, you had predicted that France would win the world cup, and it won.
True Negative:
When you predicted negative, and it's true. You had predicted that England would not win and it lost.
False Positive:
Your prediction is positive, and it is false.
You had predicted that England would win, but it lost.
False Negative:
Your prediction is negative, and result it is also false.
You had predicted that France would not win, but it won.
You should remember that we describe predicted values as either True or False or Positive and Negative.
How to Calculate a Confusion Matrix
Here, is step by step process for calculating a confusion Matrix in data mining
- Step 1) First, you need to test dataset with its expected outcome values.
- Step 2) Predict all the rows in the test dataset.
- Step 3) Calculate the expected predictions and outcomes:
- The total of correct predictions of each class.
- The total of incorrect predictions of each class.
After that, these numbers are organized in the below-given methods:
- Every row of the matrix links to a predicted class.
- Every column of the matrix corresponds with an actual class.
- The total counts of correct and incorrect classification are entered into the table.
- The sum of correct predictions for a class go into the predicted column and expected row for that class value.
- The sum of incorrect predictions for a class goes into the expected row for that class value and the predicted column for that specific class value.
Other Important Terms using a Confusion matrix
- Positive Predictive Value(PVV): This is very much near to precision. One significant difference between the two-term is that PVV considers prevalence. In the situation where the classes are perfectly balanced, the positive predictive value is the same as precision.
- Null Error Rate: This term is used to define how many times your prediction would be wrong if you can predict the majority class. You can consider it as a baseline metric to compare your classifier.
- F Score: F1 score is a weighted average score of the true positive (recall) and precision.
- Roc Curve: Roc curve shows the true positive rates against the false positive rate at various cut points. It also demonstrates a trade-off between sensitivity (recall and specificity or the true negative rate).
- Precision: The precision metric shows the accuracy of the positive class. It measures how likely the prediction of the positive class is correct.

The maximum score is 1 when the classifier perfectly classifies all the positive values. Precision alone is not very helpful because it ignores the negative class. The metric is usually paired with Recall metric. Recall is also called sensitivity or true positive rate.
- Sensitivity: Sensitivity computes the ratio of positive classes correctly detected. This metric gives how good the model is to recognize a positive class.

Why you need Confusion matrix?
Here are pros/benefits of using a confusion matrix.
- It shows how any classification model is confused when it makes predictions.
- Confusion matrix not only gives you insight into the errors being made by your classifier but also types of errors that are being made.
- This breakdown helps you to overcomes the limitation of using classification accuracy alone.
- Every column of the confusion matrix represents the instances of that predicted class.
- Each row of the confusion matrix represents the instances of the actual class.
- It provides insight not only the errors which are made by a classifier but also errors that are being made.















0 Comments